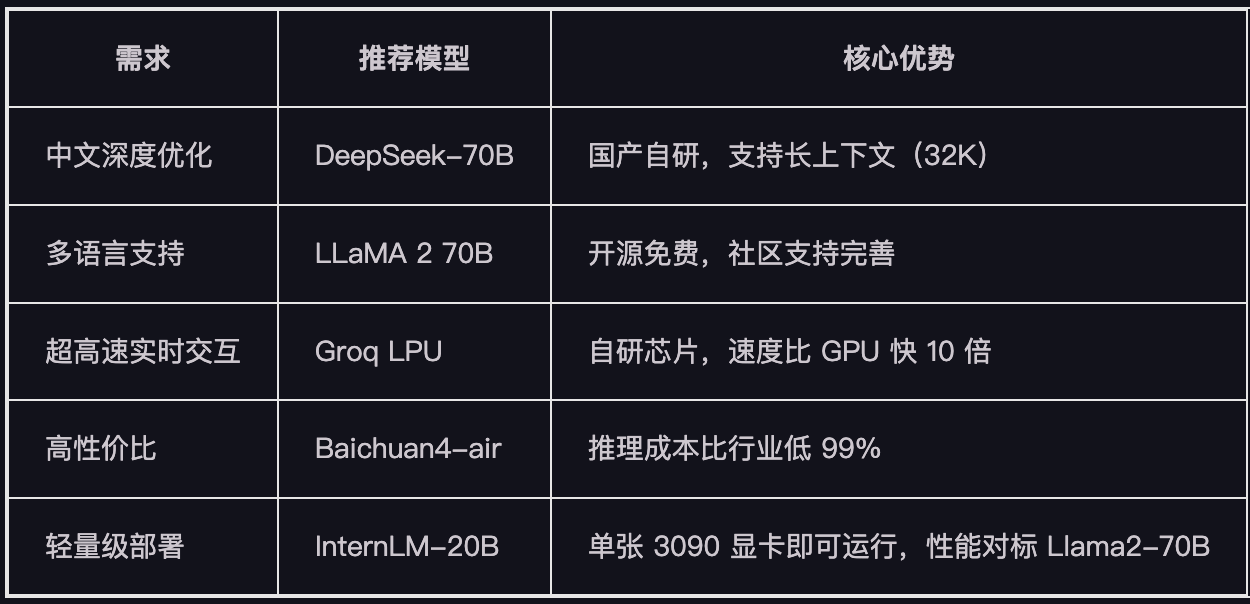
为什么要本地化部署大模型?
· 数据安全:敏感数据不出企业内网,避免泄露风险。
· 成本可控:长期使用比云服务便宜 50% 以上(例如 DeepSeek-R1 70B 本地部署年成本约 10 万,云服务月租 20 万 +)。
· 自主可控:模型可随意定制,支持私有化 API 接口。
主流大模型本地化部署对比表(价格 / 配置 / 速度 / 场景)
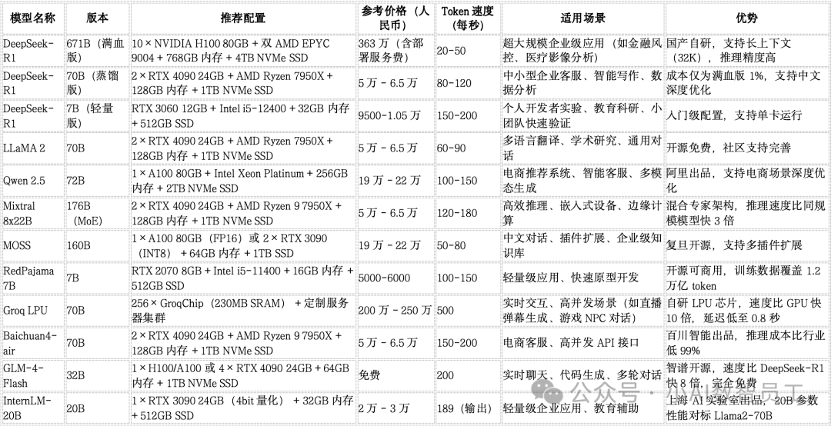
选购建议:按预算和需求匹配
1. 个人开发者 / 学生党(预算 < 1 万)
· 推荐模型:DeepSeek-7B、RedPajama-7B
· 配置:RTX 3060 + 32GB 内存(总成本约 1 万)
· 用途:写代码、做实验、简单对话机器人
· 优势:成本低,支持单卡运行,适合快速验证想法。
2. 中小企业(预算 5 万 - 20 万)
· 推荐模型:DeepSeek-70B、LLaMA 2 70B、Baichuan4-air
· 配置:2×RTX 4090 + 128GB 内存(总成本约 6 万)
· 用途:客服机器人、智能写作、数据分析
· 优势:性价比高,支持中文优化,适合快速落地业务。
3. 大型企业 / 科研机构(预算 > 100 万)
· 推荐模型:DeepSeek-R1 671B、Groq LPU、GLM-4
· 配置:H100 集群或 GroqChip 集群(总成本 200 万 +)
· 用途:金融风控、医疗影像分析、实时交互系统
· 优势:性能天花板,支持超大规模数据处理。
避坑指南:这些坑千万别踩!
1. 盲目追求大模型:70B 模型已能满足 90% 的场景需求,671B 模型性价比极低(成本 300 万 +,速度仅比 70B 快 20%)。
2. 忽视显存需求:例如 DeepSeek-R1 671B 需要 480GB 显存,必须多卡并联,单卡 A100 无法运行。
3. 低估运维成本:硬件电费每月约 1 万(以 10 张 H100 为例),还需专业工程师维护。
4. 忽略国产化方案:百度昆仑芯 P800 单机 8 卡方案成本比英伟达低 65%,适合敏感行业。
免费资源推荐
· DeepSeek-7B:完全免费,支持商用。
· GLM-4-Flash:开源免费,速度比 DeepSeek-R1 快 8 倍。
· RedPajama-7B:开源可商用,训练数据覆盖 1.2 万亿 token。
总结:选对模型,少走弯路!